
|
Getting your Trinity Audio player ready...
|
On the topic of Topics: What publishers need to know
At Xandr, we are actively participating in ongoing industry discussions about the future of identity, as well as carefully evaluating various emerging proposals. One of those proposals is the Topics API. Deconstructing and analyzing the Topics API helped us gain insight into the effectiveness of its inventory categorization methodology, how its categorization is affected by language, and the breadth of its domain coverage.
What is the Topics API?
The Topics API is part of a series of browser APIs Google has introduced to Chrome to help ad tech companies adapt to the deprecation of third-party cookies. More precisely, the Topics API is designed to support behavioral targeting approaches, which have historically relied on third-party cookies.
Rather than sending identified data (cookies) along the ad tech chain, Topics uses the browsing directly from a device to assign users to categories, known as “topics.” These topics are then exposed directly to ad tech vendors via the API, without ever requiring an identifier to leave the browser. Google Chrome believes this will enhance the privacy of its end users.
Because Topics lives in the browser and has been implemented in Chromium (the open-source variant of Chrome), we have been able to extract its source code, dissect its features, and simulate it in a developer environment. Given the public interest in Topics (and in the Privacy Sandbox generally), we have shared the tools and resources we have built for this study with the community. You can find them on our repository.

How Topics works
At its core, Topics relies on assigning categories that compose a tiered content category taxonomy (similar to Google AdX’s) to each website a user visits. The browser then counts how many domains have been visited for each category over a 7-day period, and assigns the top 5 categories to the user. These top 5 categories are then selectively returned to ad tech players through the Topics API, following a set of rules described here.
Internally, assigning visited domains to categories relies on a Bert classifier that only uses the hostname of the domain for its inference. This classifier is coupled with an override list with which Google overrides the result of the classifier for some domains, probably with the goal of enhancing Topics’ performance. Our analysis of Chromium’s code enabled us to extract both the classifier and the override list, and reproduce Chrome’s domain classification (as observable in Chrome Canary at chrome://topics-internals/).
Thus, we’ve been able to study Topics’ domain classification and answer the following questions:
- How does the Topics API’s inventory categorization compare with other categorizations on our platform?
- How does language affect Topics categorization?
- Are all domains classified?
How good is Topics at categorizing domains?
We compared inventory categorization by the Topics API to other content category features available on Xandr Monetize. Xandr devotes significant resources to maintaining a strict set of baseline criteria, so we can prevent unacceptable inventory from being sold on our platform. Inventory available on our platform may be tagged with content categories, brand-sensitive attributes, and intended audiences. This tagging can be implemented by the Xandr audit team or provided by sellers. Because this manual evaluation is available for Xandr inventory, it provides a useful comparison with the Bert model from the Topics API.
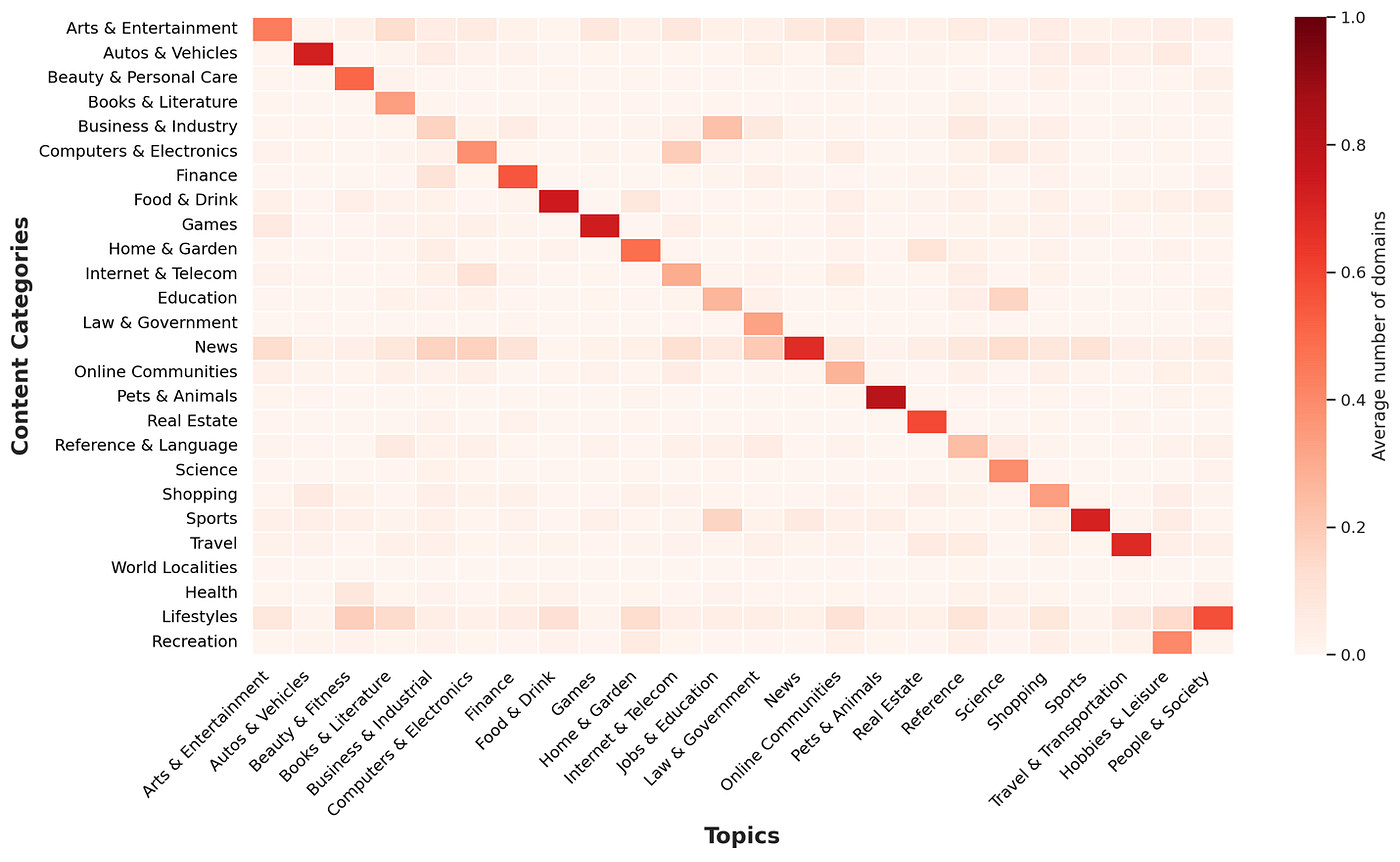
The heatmap above shows the distribution of topics across each Xandr Audit content category. (In other words, the column values add up to 1.) For the sake of clarity and simplicity, categories from both taxonomies have been reduced to their corresponding first-tier category. For example, “/Arts & Entertainment/Humor/Live Comedy” has been reduced to an element in the “Arts & Entertainment” category in the heatmap. It’s also important to note that while they appear to be very similar, the Xandr Audit and Topics taxonomies appear to be significantly different.
Globally, there’s a strong agreement between the classification types. Some Topics show a significant overlap with more than one Xandr Audit content category. However, in such cases, the content categories are still often semantically close to the Topics category they are associated with. This can be explained by the reduction to the first-tier category discussed above and the differences between the taxonomies. For instance, the “Smart Phones” category from Topics is part of Topics’ “Internet and Telecom” first-tier category, while the corresponding “Cell Phones” category from Xandr taxonomy is part of Xandr Audit’s “Computer & Electronics” first-tier category. The reduction to the first-tier categories would then lead Topics’ “Internet & Telecom” category to overlap with Xandr Audit’s “Computer & Electronics” categories.
Another interesting observation is that most of the Topics content categories have a significant overlap with the News category from Xandr Audit. This makes sense, because news encompasses a large variety of subjects, and because the Topics model can return multiple categories for a domain. For instance, in the Topics model, vogue.com is part of “Arts and Entertainment”, Fashion & Style” and “News”. Thus, a domain that Xandr Audit labels as “News” might be categorized as both “News” and “Arts & Entertainment” by Topics, leading to some overlap between Topics’ “Arts & Entertainment” and the “News” Xandr Audit label.
How does language affect Topics categorization?
Because Topics is an international feature, and its domain classification currently relies on only a single model, it is interesting to see how it handles non-English domains.
Xandr has a large international footprint, especially in Europe. Thus, we were able to collect four sets of visited domains from our traffic. We used data from France, Germany, Spain and Japan in order to compare how Topics classification performs over non-English domains. The classification for each country is then compared with Xandr Audit classification, resulting in the following heatmaps.

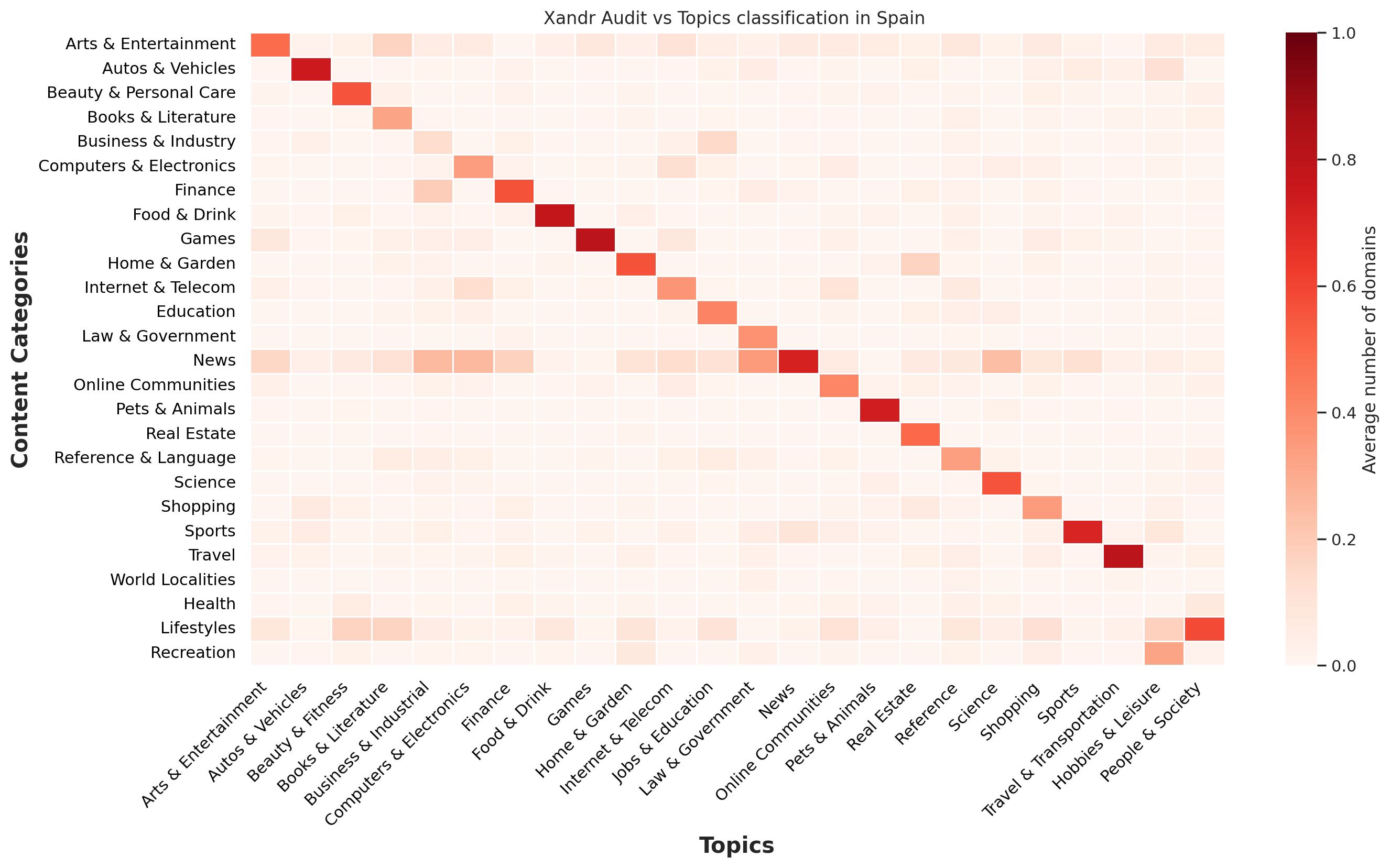
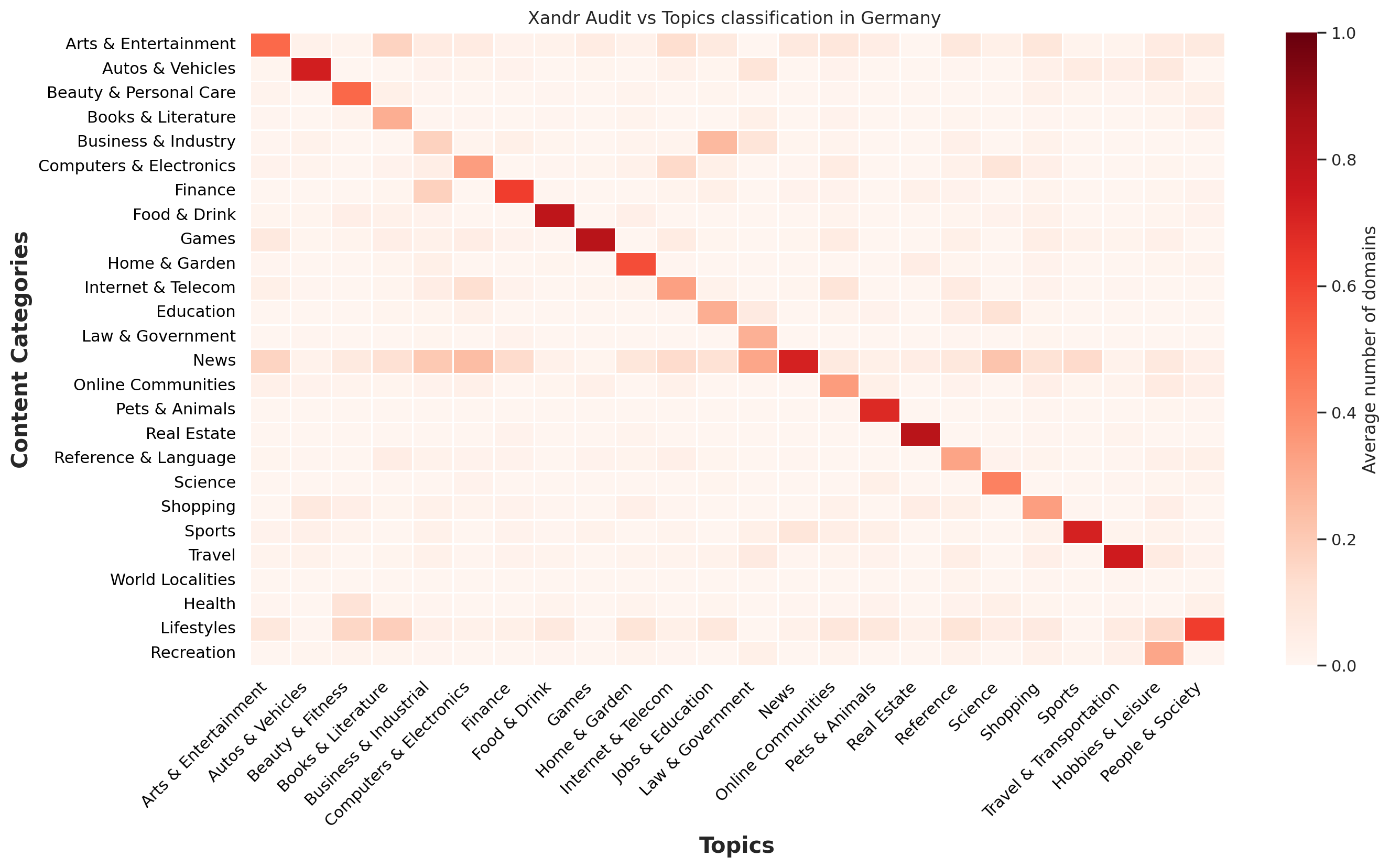
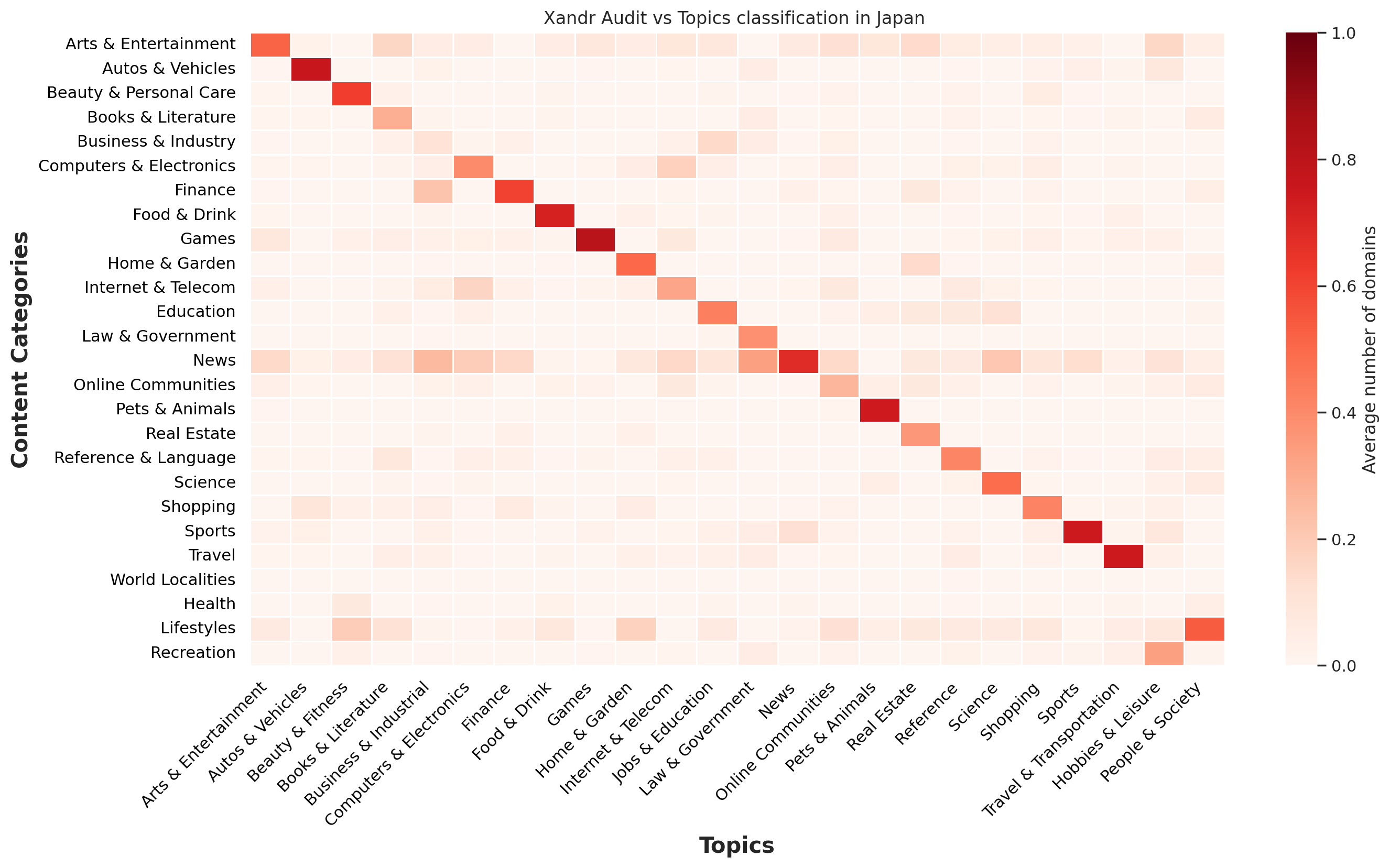
Overall, the agreement between both classifications is fairly significant, and very similar to what we previously observed across our global traffic. This seems to indicate that Topics is suitable for international needs.
Are all domains classified?
The short answer is: no. As we discussed previously, the model is a multi-label classifier, and it can assign from zero to five categories to a domain. Hence, some domains do not have any label, meaning they will not contribute to the user’s topics. The following table shows the proportion of unique domains without assigned topics for global traffic, as well as for traffic from the US, Spain, Japan, Germany and France.
| Traffic | % of domains without topic |
|---------|----------------------------|
| Global | 9.40 |
| US | 12.40 |
| Spain | 10.76 |
| Japan | 9.59 |
| Germany | 9.78 |
| France | 3.48 |
The proportion of domains without topics is not negligible: up to 12% of unique domains for our US traffic were not associated with Topics. Notably, this includes significant domains such as fandom.com or doctissimo.fr, which are ranked by similarweb.com as the 46th global domain and the 3rd health-related French domain, respectively. It also includes domains with semantically explicit hostnames, such as horoscope.com, conservativejournalreview.com and thesologlobetrotter.com. This is obviously not ideal and shows that the model performance isn’t perfect. However, we still find that its performance is acceptable, given that the model is only using the hostname to qualify the domain’s content.
Summary
We successfully extracted the Topics model from the Chrome browser, and were able to apply it to our datasets. Based on our experiments, the model performed well against human classification techniques. This suggests that the Topics API works as a categorization tool alone, including for non-English domains.
What’s Next?
While the studied model is instrumental to understanding the Topics API, it only covers one facet of it. Observing how user browsing histories are qualified, as well as how the ad tech players’ footprint affects how many topics they receive, will be crucial for completely understanding the proposal. Stay tuned!
Co-authored by Oumaima BENBAHAKKA, Dr. Paul Farrow, Dr. Romain Quéré and Dr. Yana Volkovich
A version of this article was published here.

